AI in embedded systems - how it works!
Artificial Intelligence (AI) is currently a hot topic and is being used more and more frequently by both individuals and businesses. With the emergence of Large Language Models (LLMs), AI has entered a new era in recent years. Tasks that seemed unthinkable just five years ago can now be handled effortlessly.
Another type of AI has even defeated the world's best Go player in his own game – a game so complex that it has more possible moves than there are atoms in the universe. Such complexity makes it impossible to calculate all possible variations in advance.
Another impressive example is the development of an AI capable of predicting the folding of proteins – a physics problem that had remained unsolved despite decades of research.
These advancements could contribute to the development of entirely new drugs and revolutionize medicine.
However, these high-performance AI systems require enormous computing power and typically run on supercomputers or powerful graphics cards. But such resources are not always available or practical.
Sometimes, AI applications need to run on small, cost-effective computers or even microcontrollers – devices that often have limited processing power and memory and need to operate on a battery for months or even years.
In recent years, numerous solutions have emerged for such applications. While it is (still) not possible to run a Large Language Model on a microcontroller, many other AI applications have now become feasible.
This article explores the processes involved in AI systems and how they can be implemented on embedded devices.
Both the advantages and disadvantages, as well as the associated challenges, will be discussed.
AI technologies
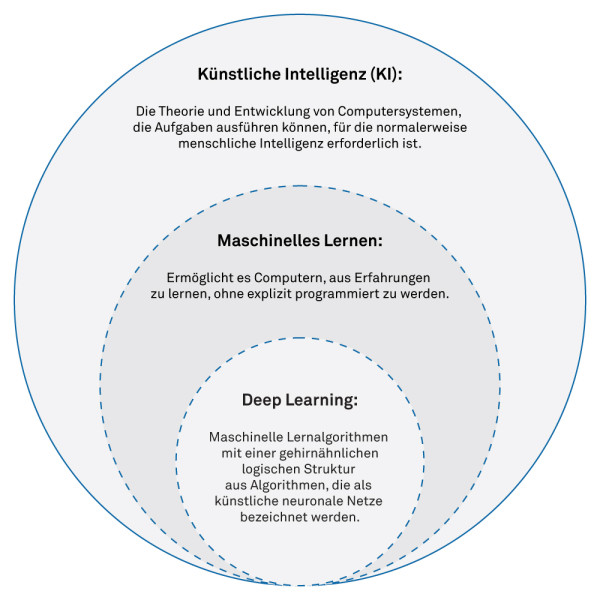
The term AI encompasses a variety of technologies that are used for different tasks. Currently, there is a lot of discussion about Deep Learning, which is based on neural networks and functions similarly to a biological brain. However, besides Deep Learning, there are numerous other technologies often referred to as "Traditional Machine Learning":
- Decision Trees
- Support Vector Machines
- Hidden Markov Models
- Bayesian Networks
- Linear Regression
- K-Means Clustering
These technologies are also widely used, particularly in scenarios where decisions need to be transparent and understandable.
In industrial systems, where features are limited, or in embedded systems, where performance, memory, and cost play a crucial role, Deep Learning is not always the most suitable option.
Technologies within AI
Thanks to the steadily increasing computing power now available even in embedded systems, Deep Learning is being used more frequently.
It opens up numerous possibilities that would be difficult or impossible to achieve with conventional technologies. Additionally, training a neural network is often easier than developing and implementing complex alternative solutions.
Why AI makes sense on an embedded device
The use of AI, such as a neural network, on an embedded device offers numerous advantages.
One key benefit is the automatic identification of relevant features from the given data.
Manual extraction is not only time-consuming but also requires deep expertise in both the data and potential algorithms.
Here, AI can assist by efficiently identifying the right features and even recognizing unexpected patterns that might elude human experts.
Running AI directly on an embedded device, instead of a networked application, also provides additional advantages:
- No internet connection required, ensuring privacy protection
- Operates on battery-powered systems
- Real-time capability
- Potentially lower hardware costs
However, there are also some disadvantages:
- Limited computing power: Large models do not run in real time
- Limited memory: Only the smallest models can be used
- Accuracy is often reduced due to smaller models
Artificial neural networks and deep learning
An artificial neural network is inspired by the functionality of biological neurons.
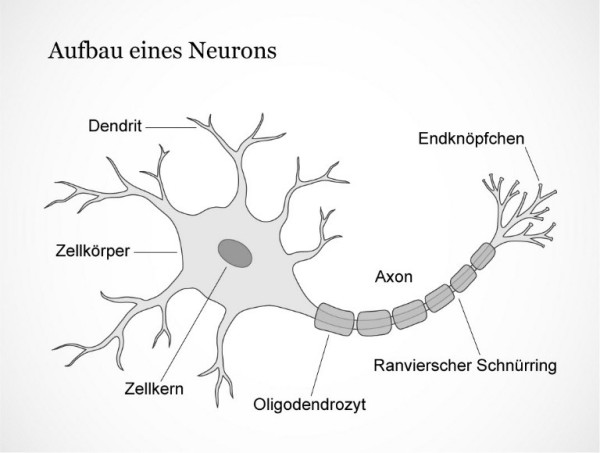
The Biological Neuron
Neurons in our brain are specialized cells that transmit action potentials. They mainly consist of dendrites (inputs), the cell nucleus, and the axon (output).
A neuron receives signals from other neurons or receptors through its synapses, which are located on the dendrites. A single neuron can have between 1 and 100,000 synapses, with an average of about 10,000.
The strength of each synapse determines how strongly the neuron is excited by this input. These excitations are summed in the cell body. When a certain threshold potential is reached, the neuron triggers an action potential.
This action potential is transmitted through the axon to other neurons. The output is binary: either an action potential is triggered or not. The more action potentials the cell fires in a given time span, the stronger the stimulus.
Source: www.dasgehirn.info
Learning occurs through the adjustment of synapses. When two neurons are frequently active simultaneously, their connection is strengthened. This principle can be summarized by the phrase "Neurons that fire together, wire together." It is the primary mechanism for learning and memory formation, although there are many other mechanisms that are not explained here.
Artificial Neural Networks
Similar to biology, there are also neurons here. However, in this context, they are only referred to as inputs and outputs, each with different weights.
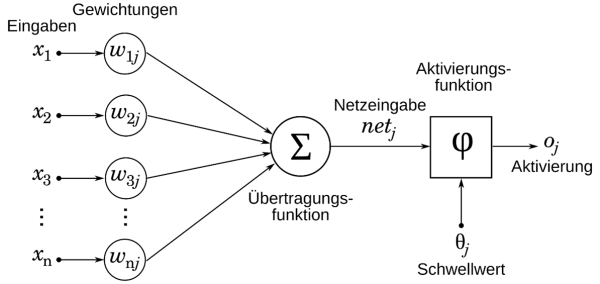
The artificial neuron. Source: wikipedia.org
Each input is multiplied by a weight. The results of these multiplications are then summed. Subsequently, an activation function determines whether the output is active or not. This highlights the most frequently performed operations in computing: multiplication and addition.
To simplify computation and storage, neurons are organized into layers.
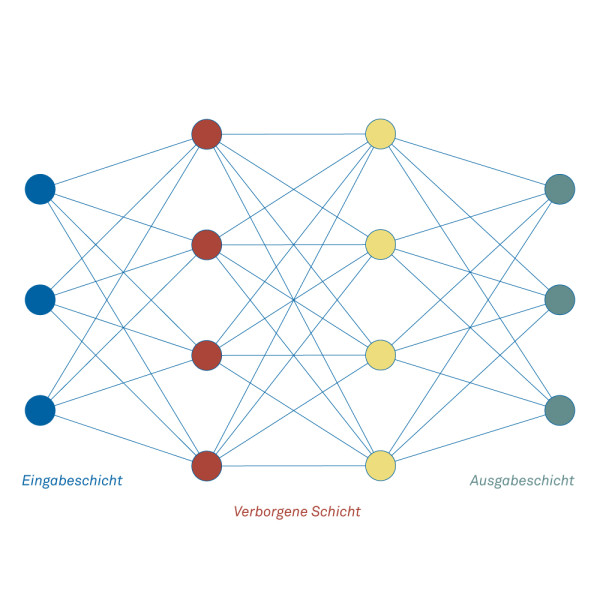
The structure of a neuronal network
Simple neural networks consist of an input layer, usually a hidden layer, and an output layer. These are already capable of solving many tasks. Computation starts at the input layer. Once all outputs are computed, the next layer can be calculated, and so on until the output layer.
Example: Classification of Animal Species.
At the input layer, various characteristics are assigned. A characteristic could be size, length, or color, for example. Each characteristic is assigned to an input. If the network is properly trained, only the neuron corresponding to the appropriate animal will be active at the output.
Training
To train a neural network, the weights of the inputs for each neuron must be adjusted so that a specific pattern at the input layer produces the desired pattern at the output layer. Various algorithms are available for this adjustment, with backpropagation being one of the most well-known and widely used.
There are different types of learning in artificial intelligence, each following different approaches:
- Supervised Learning:
In supervised learning, the neural network receives both input data and corresponding output data (labels). The learning algorithm adjusts the network parameters to minimize the error between the predicted and actual outputs. This method is the most commonly used learning type, especially in embedded systems, as it is precise and well-controlled. - Unsupervised Learning:
Here, the model is only presented with input data without predefined labels. The learning algorithm independently creates a statistical model that identifies patterns or categories in the data. This method is particularly useful for recognizing structures or groupings in unlabeled data. - Reinforcement Learning:
In reinforcement learning, the model interacts with its environment to learn through trial and error. A classic example is a strategy game where the model plays against itself and learns optimal strategies through rewards (for good actions) or penalties (for bad actions). This method is particularly useful for applications where the system must make independent decisions.
Deep Learning
For demanding tasks such as object recognition in images, natural language recognition, or chatbots, neural networks with a significantly higher number of neurons are required. Once a network has more than two hidden layers, it is already referred to as deep learning – though in practice, there are often many more layers.
Each layer in such a network takes on specialized tasks. In object recognition, for example, convolutional layers are frequently used. These layers apply a convolution (similar to classical image processing) between the image and a filter (kernel) to extract features such as edges or textures. Pooling layers then reduce the data volume by condensing the most important information. The process is often concluded with a fully connected layer, which calculates the final result from the extracted features.
The challenge lies in cleverly combining the right layers and optimally adjusting their size.
Development steps of an embedded AI project
1. Collecting Training Data
Collecting high-quality training data is a crucial step in developing an AI model. This process can be quite resource-intensive but directly impacts the model's performance. The data must be carefully selected and representative of all categories the model needs to learn. Poor or insufficient data can make training ineffective and lead to unsatisfactory results.
In supervised learning, which is often applied in embedded systems, data also needs to be annotated (labeling).
In practice, training data is often collected manually. However, there are numerous publicly available datasets and libraries that can be used to save time and resources. These pre-existing datasets are particularly useful for accelerating the development process.
Alternatively, data can also be artificially generated or expanded through data augmentation. This involves artificially multiplying existing data by applying transformations such as rotation, scaling, or mirroring to increase dataset diversity.
The simplest solution is to use a pre-trained model whenever possible. Such models can either be used directly or further improved through additional training with custom data. Another efficient method is transfer learning, where a large, pre-trained model is adapted to specific requirements. This not only saves time but also reduces the need for large amounts of custom training data.
2. Model Selection and Design
In this step, a suitable network type is chosen based on the application. Examples include Convolutional Neural Networks (CNNs) for image processing or Recurrent Neural Networks (RNNs) for time series analysis. The model size must be adapted to the target device’s resources to ensure efficient execution.
3. Training the Model
Model training is typically performed on a high-performance PC or server equipped with GPUs or TPUs. During training, hyperparameters such as learning rate, batch size, and the number of layers are optimized to achieve the best possible performance. The model’s performance is then evaluated using an unseen validation dataset to prevent overfitting and ensure good generalization capabilities.
4. Model Optimization for the Target Device
To adapt the model to the limited resources of an embedded system, various optimization techniques can be applied:
- Quantization: Reducing the precision of weights, for example, from 32-bit floating-point numbers to 8-bit integer values. This saves memory and computing power.
- Pruning: Removing unnecessary neurons or connections to make the model smaller and more efficient.
- Additional Methods: Numerous other techniques exist to reduce network size and complexity, which can be implemented using specialized frameworks.
5. Deployment and Testing on the Target Device
The optimized model is integrated into the embedded system's firmware or software. It must be ensured that the model operates within the system’s memory and processing constraints. Finally, the model undergoes extensive testing to verify its functionality and performance under real-world conditions.
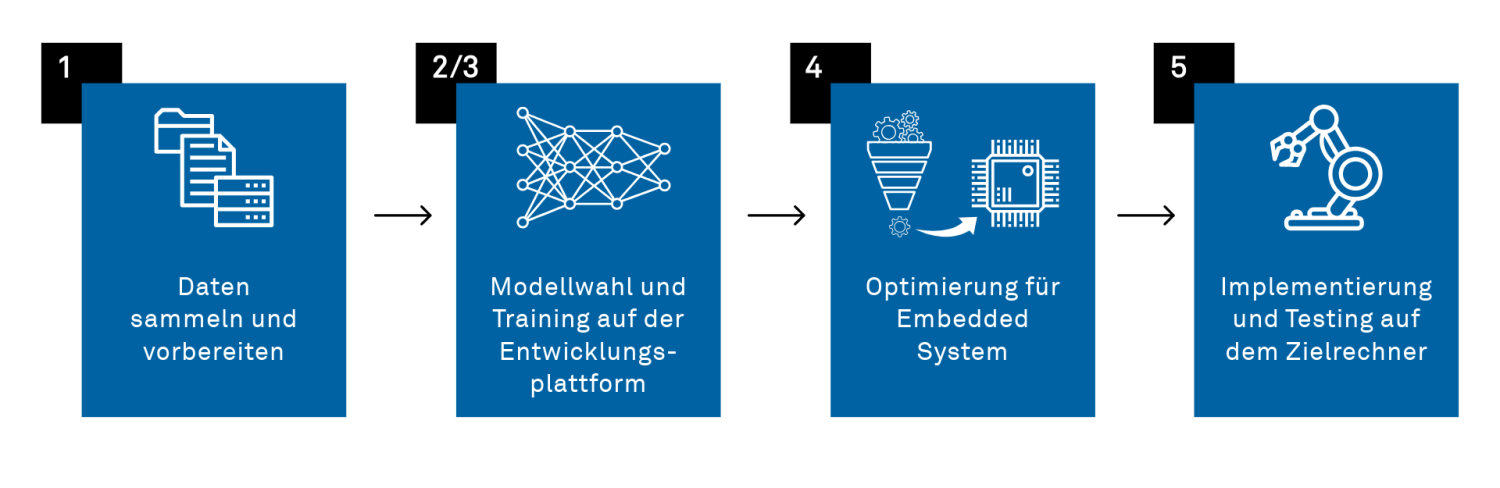
Development Steps of an Embedded AI Project
Various tools are available to support the development steps described above. Below is an overview of common libraries and frameworks for embedded AI:
| Library/Framework | Target hardware | Properties |
|---|---|---|
| TensorFlow Lite | Mobile, Embedded, Microcontroller | Lightweight, supports quantization |
| PyTorch Mobile | Mobile, Embedded | Optimized for Android/iOS |
| CMSIS-NN | ARM Cortex-M Microcontroller | Highly efficient, small footprint |
| STM32Cube.AI | STM32 Microcontroller | Optimized for STM32 hardware |
| Apache TVM | Almost everywhere | Cross-platform, model optimizations |
What happens on the target computer?
As already mentioned, the calculations mainly consist of multiplications and additions. The data is prepared in such a way that it can be processed using matrix operations. Most calculations involve matrix multiplications (the weights of the synapses of a layer) with a vector (the inputs of the neurons in that layer).
Fortunately, GPUs (graphics processing units) are ideal for such calculations, as they perform similar operations in image processing. They allow many calculations to be executed in parallel, significantly increasing efficiency. Over time, specialized hardware solutions such as the TPU (Tensor Processing Unit) and later the NPU (Neuromorphic Processing Unit) were developed, specifically optimized for deep learning.
A lot has also happened in the embedded world. There are more and more dedicated hardware solutions tailored to the computation of neural networks.
The following table presents some of these products in more detail.
| Kategorie | Typ | Merkmale | Preis | Anwendungsbeispiele |
|---|---|---|---|---|
| Gaming graphics card | Nvida GeForce 5090 | Up to 1000 W (total) Up to 3352 AI TOPS 3.3 TOPS / W 32 GB RAM | ~3000 $ | LLMs that are not too large (e.g. GPT-3, GPT-4 is already too large) |
| High-end embedded computer for AI | Nvida Jetson Orin NX | 10 – 25 W 70 – 100 AI TOPS 4 TOPS / W 16 GB RAM | ~700 $ | Small Language Models (SLM). There are many that are between 600 MB and 4 GB in size. Object recognition with the best deep neural networks and high frame rates (e.g. YOLOv7) |
| Low-power AI add-on computer | Intel Movidius Myriad X | 1.5W 4 AI TOPS 2.6 TOPS / W 2.5 MB RAM | ~80 $ | Real-time object recognition with small networks (e.g. MobileNet v2 or TinyYolo) Facial recognition and biometric authentication Optical character recognition Autonomous navigation and collision avoidance Pedestrian and vehicle recognition Predictive maintenance |
| Microcontroller with AI support | STM32N6 | 225 – 417 mW 0.6 AI TOPS 1.4 - 2.6 TOPS / W 4.2 MB RAM | ~15 $ | Voice command recognition Audio Scene Recognition Simple object recognition in images Anomaly detection Predictive maintenance Hand signal recognition Noise filter in audio signals |
| Low-power microcontroller | STM32L5 | 40 mW Very dependent on the application 256 kB RAM | ~5 $ | Keyword spotting Gesture recognition with acceleration sensor Image classification with very low resolution Anomaly detection |
Conclusion
AI is no longer limited to powerful PCs or large data centers.
It can also be deployed on embedded systems or even microcontrollers, enabling a wide range of applications.
There are now numerous tools that simplify the implementation of such projects, along with many new hardware developments featuring dedicated AI accelerators. This specialized hardware allows AI computations to be performed efficiently and with low energy consumption.
Well-known models for object recognition have been optimized for use on small devices – often with only minimal precision loss. This makes it possible today to detect or track objects in real time on a microcontroller – all while consuming only a few hundred milliwatts.
These advancements open up completely new possibilities for AI applications in areas such as transportation, Industry 4.0, the Internet of Things, and smart cities.
Our experts are happy to support you with your next embedded AI project, so don’t hesitate to contact us.
Get in touch now and start your AI-embedded project >
Still unsure?
We will soon publish another article demonstrating a practical implementation of the mentioned technologies on a small microcontroller.

Lukas Frei
MSc University of Bern and BFH in Biomedical Engineering
Embedded Software Engineer
About the author
Lukas Frei has been working as an Embedded Software Engineer at CSA for four years, specializing in the development of firmware in C/C++ for STM32 systems.
Over the past years, he has gained extensive experience in the development, testing, and optimization of firmware for a wide range of applications, including in the fields of industry, transportation, and medical technology.
With his solid experience in embedded software development and a strong interest in artificial intelligence, he brings fresh perspectives to your projects.