KI in Embedded Systemen - So geht's!
Künstliche Intelligenz (KI) ist derzeit in aller Munde und wird sowohl von Privatpersonen als auch Unternehmen immer häufiger eingesetzt. Mit dem Aufkommen von Large Language Models (LLMs) hat die KI in den letzten Jahren ein neues Zeitalter erreicht. Aufgaben, die noch vor fünf Jahren undenkbar schienen, können heute problemlos bewältigt werden.
Eine andere Art von KI hat sogar den weltbesten Go-Spieler in seinem eigenen Spiel geschlagen – ein Spiel, das so komplex ist, dass es mehr mögliche Spielzüge gibt als Atome im Universum. Eine solche Komplexität macht es unmöglich, alle Varianten im Voraus zu berechnen.
Ein weiteres beeindruckendes Beispiel ist die Entwicklung einer KI, die in der Lage ist, die Faltung von Proteinen vorherzusagen – ein Problem der Physik, das trotz jahrzehntelanger Forschung bislang ungelöst war.
Diese Fortschritte könnten dazu beitragen, völlig neue Medikamente zu entwickeln und die Medizin zu revolutionieren.
Allerdings erfordern diese Hochleistungs-KI-Systeme enorme Rechenleistung und laufen in der Regel auf Supercomputern oder leistungsstarken Grafikkarten. Doch nicht immer sind solche Ressourcen verfügbar oder sinnvoll.
Manchmal sollen KI-Anwendungen auf kleinen, kostengünstigen Rechnern oder sogar Mikrocontrollern laufen – Geräte, die oft nur über begrenzte Leistung und Speicher verfügen und monate- oder jahrelang mit einer Batterie betrieben werden müssen.
Für solche Anwendungen sind in den letzten Jahren zahlreiche Lösungen entstanden. Zwar ist es (noch) nicht möglich, ein Large Language Model auf einem Mikrocontroller zu betreiben, aber viele andere KI-Anwendungen sind mittlerweile machbar geworden.
Dieser Artikel beleuchtet, welche Prozesse in KI-Systemen ablaufen und wie diese auf Embedded-Geräten implementiert werden.
Dabei werden sowohl die Vor- und Nachteile als auch die damit verbundenen Herausforderungen dargestellt.
KI Technologien
Der Begriff KI umfasst eine Vielzahl von Technologien, die für unterschiedliche Aufgaben eingesetzt werden. Aktuell wird häufig über Deep Learning gesprochen, das auf neuronalen Netzen basiert und ähnlich wie ein biologisches Gehirn funktioniert.
Neben Deep Learning gibt es jedoch zahlreiche andere Technologien, die oft als "Traditional Machine Learning" bezeichnet werden:
- Entscheidungsbäume (Decision Trees)
- Support Vector Machines
- Hidden Markov Models
- Bayes'sche Netze (Bayesian Networks)
- Lineare Regression
- K-Means-Clustering
Diese Technologien finden ebenfalls breite Anwendung, insbesondere in Szenarien, in denen Entscheidungen transparent und nachvollziehbar sein müssen.
In industriellen Systemen, bei denen die Merkmale begrenzt sind, oder in eingebetteten Systemen, wo Leistung, Speicher und Kosten eine wichtige Rolle spielen, ist der Einsatz von Deep Learning nicht immer die geeignetste Variante.
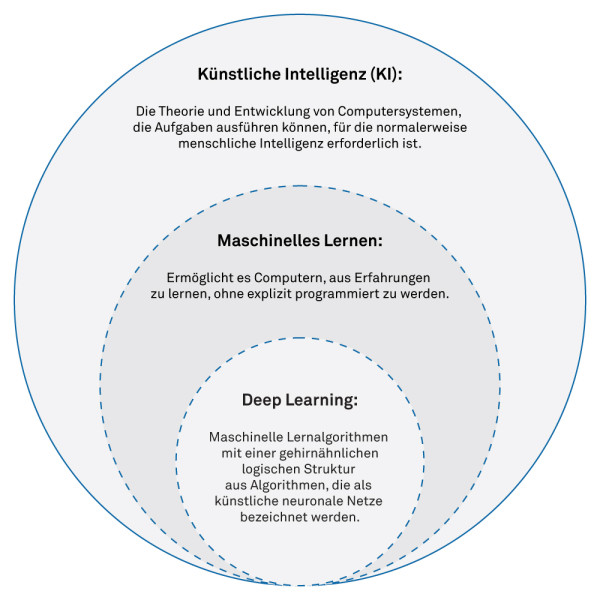
Technologien innerhalb der KI
Dank der stetig wachsenden Rechenleistung, die mittlerweile auch in Embedded Systemen zur Verfügung steht, findet Deep Learning immer häufiger Anwendung.
Es eröffnet zahlreiche Möglichkeiten, die mit herkömmlichen Technologien nur schwer oder gar nicht realisierbar wären.
Zudem ist es oft einfacher, ein neuronales Netz zu trainieren, als komplexe, alternative Lösungen zu entwickeln und umzusetzen.
Warum KI auf einem Embedded-Gerät Sinn macht
Der Einsatz einer KI, wie zum Beispiel eines Neuronalen Netzwerks, auf einem Embedded Gerät bietet zahlreiche Vorteile.
Hervorzuheben ist hierbei die automatische Identifikation der relevanten Merkmale aus den gegebenen Daten.
Eine manuelle Extrahierung ist einerseits zeitaufwändig und bedingt andererseits tiefgehendes Fachwissen zu den Daten wie auch zu möglichen Algorithmen.
Hier kann eine KI unterstützen, effizient die richtigen Features zu identifizieren und selbst für Fachpersonen unerwartete Muster zu erkennen.
Der Betrieb einer KI direkt auf einem Embedded Gerät, anstelle einer vernetzten Anwendung, bietet zudem weitere Vorteile:
- Keine Internetverbindung notwendig und dadurch Schutz der Privatsphäre
- Lauffähig auf batteriebetriebenen Systemen
- Echtzeitfähigkeit
- Tendenziell tiefere Hardwarekosten
Dem gegenüber stehen einige Nachteile:
- Limitierte Rechenleistung: Grosse Modelle laufen nicht in Echtzeit
- Limitierter Speicher: Nur die kleinsten Modelle sind einsetzbar
- Die Genauigkeit wird meistens durch kleinere Modelle reduziert
Künstliche Neuronale Netze und Deep Learning
Ein künstliches neuronales Netz ist von der Funktionsweise biologischer Neuronen inspiriert.
Aus diesem Grund ist es sinnvoll, zunächst die Arbeitsweise biologischer Neuronen zu betrachten, bevor wir die Parallelen zu künstlichen Netzen und ihre Funktionsweise im Detail beleuchten.
Das biologische Neuron
Neuronen in unserem Gehirn sind spezialisierte Zellen, die Aktionspotenziale weiterleiten. Sie bestehen hauptsächlich aus Dendriten (den Eingängen), dem Zellkern und dem Axon (dem Ausgang).
Ein Neuron empfängt Signale von anderen Neuronen oder Rezeptoren über seine Synapsen, die sich an den Dendriten befinden. Ein einzelnes Neuron kann zwischen 1 und 100.000 Synapsen haben, durchschnittlich sind es etwa 10.000.
Die Stärke jeder Synapse bestimmt, wie stark das Neuron durch diesen Eingang erregt wird. Diese Erregungen werden im Zellkörper summiert. Wenn ein bestimmtes Schwellenpotenzial erreicht wird, löst das Neuron ein Aktionspotenzial aus.
Dieses Aktionspotenzial wird über das Axon an andere Neuronen weitergeleitet. Der Ausgang ist dabei binär: Entweder wird ein Aktionspotenzial ausgelöst oder nicht. Je mehr Aktionspotenziale die Zelle in einer bestimmten Zeitspanne abfeuert, desto stärker ist der Reiz.
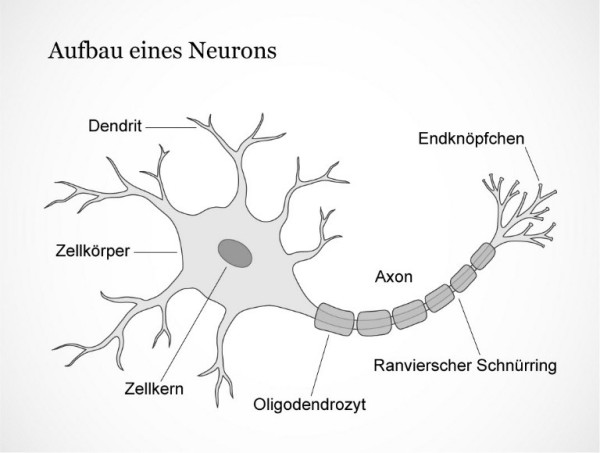
Source: www.dasgehirn.info
Das Lernen erfolgt durch die Anpassung der Synapsen. Wenn zwei Neuronen häufig gleichzeitig aktiv sind, wird ihre Verbindung gestärkt. Dieses Prinzip lässt sich mit dem Satz "Neurons that fire together, wire together" zusammenfassen. Es handelt sich um den Hauptmechanismus für Lernen und Gedächtnisbildung, obwohl es noch viele weitere Mechanismen gibt, die hier nicht erläutert werden.
Künstliche Neuronale Netze
Ähnlich wie in der Biologie gibt es auch hier Neuronen. Allerdings spricht man in diesem Zusammenhang nur noch von Eingängen und Ausgängen, die unterschiedliche Gewichtungen haben.
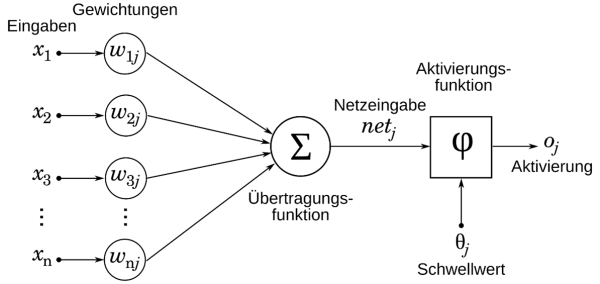
Das künstliche Neuron. Source: wikipedia.org
Die verschiedenen Eingänge werden jeweils mit einer Gewichtung multipliziert. Die Ergebnisse dieser Multiplikationen werden dann summiert. Anschliessend entscheidet eine Aktivierungsfunktion, ob der Ausgang aktiv ist oder nicht. Hier wird deutlich, welche Operationen im Rechner am häufigsten durchgeführt werden: Multiplizieren und Addieren.
Um das Rechnen und Abspeichern zu vereinfachen, sind die Neuronen in Schichten organisiert.
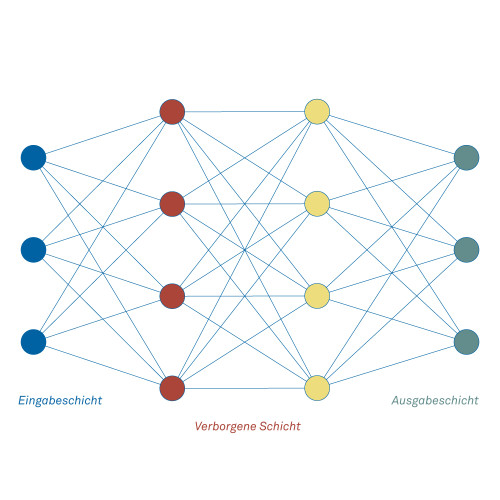
Der Aufbau eines Neuronalen Netzes
Einfache Neuronale Netze bestehen aus einer Eingabeschicht, meistens einer verborgenen Schicht und einer Ausgabeschicht. Damit lassen sich bereits viele Aufgaben lösen. Das Rechnen beginnt an der Eingabeschicht. Sobald alle Ausgänge berechnet sind, kann die nächste Schicht berechnet werden, und so weiter bis zur Ausgabeschicht.
Beispiel: Klassifizierung von Tierarten.
An der Eingabeschicht werden verschiedene Merkmale angelegt. Ein Merkmal könnte beispielsweise die Grösse, Länge oder Farbe sein. Jedes Merkmal wird einem Eingang zugeordnet. Wenn das Netz richtig trainiert ist, wird am Ausgang nur das Neuron aktiv sein, das dem entsprechenden Tier zugeordnet ist.
Trainieren
Um ein neuronales Netz zu trainieren, müssen die Gewichtungen der Eingänge für jedes Neuron so angepasst werden, dass bei einem bestimmten Muster an der Eingabeschicht das gewünschte Muster an der Ausgabeschicht erzeugt wird. Für diese Anpassung stehen verschiedene Algorithmen zur Verfügung, wobei Backpropagation einer der bekanntesten und am häufigsten verwendeten ist.
Es gibt verschiedene Arten des Lernens in der künstlichen Intelligenz, die jeweils unterschiedliche Ansätze verfolgen:
- Supervised Learning (Überwachtes Lernen):
Beim Supervised Learning erhält das neuronale Netz sowohl Eingangsdaten als auch die zugehörigen Ausgangsdaten (Labels). Der Lernalgorithmus passt die Parameter des Netzwerks an, um den Fehler zwischen den vorhergesagten und den tatsächlichen Ausgaben zu minimieren. Diese Methode ist die am häufigsten verwendete Art des Lernens, insbesondere in Embedded Systems, da sie präzise und gut kontrollierbar ist. - Unsupervised Learning (Unüberwachtes Lernen):
Hier werden dem Modell nur die Eingangsdaten ohne vorgegebene Labels präsentiert. Der Lernalgorithmus erstellt selbstständig ein statistisches Modell, das Muster oder Kategorien in den Daten erkennt. Diese Methode eignet sich besonders gut für die Erkennung von Strukturen oder Gruppierungen in unmarkierten Daten. - Reinforcement Learning (Bestärkendes Lernen):
Beim Reinforcement Learning interagiert das Modell mit seiner Umgebung, um durch Versuch und Irrtum zu lernen. Ein klassisches Beispiel ist ein Strategiespiel, bei dem das Modell gegen sich selbst spielt und durch Belohnungen (für gute Aktionen) oder Bestrafungen (für schlechte Aktionen) lernt, optimale Strategien zu entwickeln. Diese Methode ist besonders nützlich für Anwendungen, bei denen das System eigenständig Entscheidungen treffen muss.
Deep Learning
Für anspruchsvolle Aufgaben wie Objekterkennung in Bildern, natürliche Spracherkennung oder Chat-Bots sind neuronale Netze mit einer deutlich höheren Anzahl von Neuronen erforderlich. Sobald ein Netzwerk mehr als zwei verborgene Schichten besitzt, spricht man bereits von Deep Learning – in der Praxis sind es jedoch oft deutlich mehr.
Jede Schicht in einem solchen Netzwerk übernimmt dabei spezialisierte Aufgaben. Bei der Objekterkennung kommen beispielsweise häufig Convolutional Layers zum Einsatz. Diese Schichten wenden, ähnlich wie in der klassischen Bildverarbeitung, eine Faltung (Convolution) zwischen dem Bild und einem Filter (Kernel) an, um Merkmale wie Kanten oder Texturen zu extrahieren. Anschliessend reduzieren Pooling Layers die Datenmenge, indem sie die wichtigsten Informationen verdichten. Den Abschluss bildet oft ein Fully Connected Layer, der aus den extrahierten Merkmalen das endgültige Ergebnis berechnet.
Die Kunst besteht darin, die richtigen Schichten geschickt zu kombinieren und deren Grösse optimal anzupassen.
Entwicklungsschritte eines Embedded KI Projektes
1. Trainingsdaten sammeln
Das Sammeln hochwertiger Trainingsdaten ist ein entscheidender Schritt bei der Entwicklung eines KI-Modells. Dieser Prozess kann zwar mit erheblichem Aufwand verbunden sein, hat jedoch direkten Einfluss auf die Leistungsfähigkeit des Modells. Die Daten müssen sorgfältig ausgewählt und repräsentativ für alle Kategorien sein, die das Modell lernen soll. Schlechte oder unzureichende Daten können das Training unwirksam machen und zu unbefriedigenden Ergebnissen führen.
Beim überwachten Lernen, was auf Embedded Systeme oft angewendet wird, müssen die Daten noch annotiert werden (Labeling).
In der Praxis werden Trainingsdaten oft manuell gesammelt. Es gibt jedoch zahlreiche öffentlich verfügbare Datensätze und Bibliotheken, die genutzt werden können, um Zeit und Ressourcen zu sparen. Diese vorgefertigten Datensätze eignen sich besonders gut, um den Entwicklungsprozess zu beschleunigen.
Alternativ können Daten auch künstlich generiert oder durch Data Augmentation erweitert werden. Dabei werden vorhandene Daten durch Transformationen wie Rotation, Skalierung oder Spiegelung künstlich vervielfältigt, um die Vielfalt des Datensatzes zu erhöhen.
Die einfachste Lösung besteht darin, ein bereits trainiertes Modell zu verwenden, sofern dies möglich ist. Solche Modelle können entweder direkt eingesetzt oder durch zusätzliches Training mit eigenen Daten weiter verbessert werden. Eine weitere effiziente Methode ist das Transfer Learning, bei dem ein grosses, vortrainiertes Modell an spezifische Anforderungen angepasst wird. Dies spart nicht nur Zeit, sondern reduziert auch den Bedarf an grossen Mengen eigener Trainingsdaten.
2. Modellauswahl und -design
In diesem Schritt wird ein geeigneter Netzwerktyp ausgewählt, der zur jeweiligen Anwendung passt. Beispiele hierfür sind Convolutional Neural Networks (CNNs) für Bildverarbeitung oder Recurrent Neural Networks (RNNs) für Zeitreihenanalysen. Dabei muss die Grösse des Modells an die Ressourcen des Zielrechners angepasst werden, um eine effiziente Ausführung zu gewährleisten.
3. Training des Modells
Das Training des Modells erfolgt typischerweise auf einem leistungsstarken PC oder Server, der mit GPUs oder TPUs ausgestattet ist. Während des Trainings werden Hyperparameter wie die Lernrate, die Batch-Grösse und die Anzahl der Schichten optimiert, um die bestmögliche Leistung zu erzielen. Anschliessend wird die Modellleistung auf einem noch nicht verwendeten Validierungsdatensatz bewertet, um Überanpassung (Overfitting) zu vermeiden und die Generalisierungsfähigkeit des Modells sicherzustellen.
4. Modelloptimierung für den Zielrechner
Um das Modell an die begrenzten Ressourcen eines Embedded Systems anzupassen, können verschiedene Optimierungstechniken angewendet werden:
· Quantisierung: Die Genauigkeit der Gewichte wird reduziert, beispielsweise von 32-Bit-Fliesskommazahlen auf 8-Bit-Integer-Werte. Dies spart Speicherplatz und Rechenleistung.
· Pruning: Unwichtige Neuronen oder Verbindungen werden entfernt, um das Modell zu verkleinern und effizienter zu machen.
· Weitere Ansätze: Es gibt zahlreiche weitere Methoden zur Reduzierung der Netzwerkgrösse und -komplexität, die mithilfe spezialisierter Frameworks umgesetzt werden können.
5. Implementierung auf dem Zielrechner und Testing
Das optimierte Modell wird in die Firmware oder Software des Embedded Systems integriert. Dabei muss sichergestellt werden, dass das Modell innerhalb der Speicher- und Rechenlimits des Systems arbeitet. Anschliessend wird das Modell umfassend getestet, um seine Funktionsfähigkeit und Leistung unter realen Bedingungen zu überprüfen.
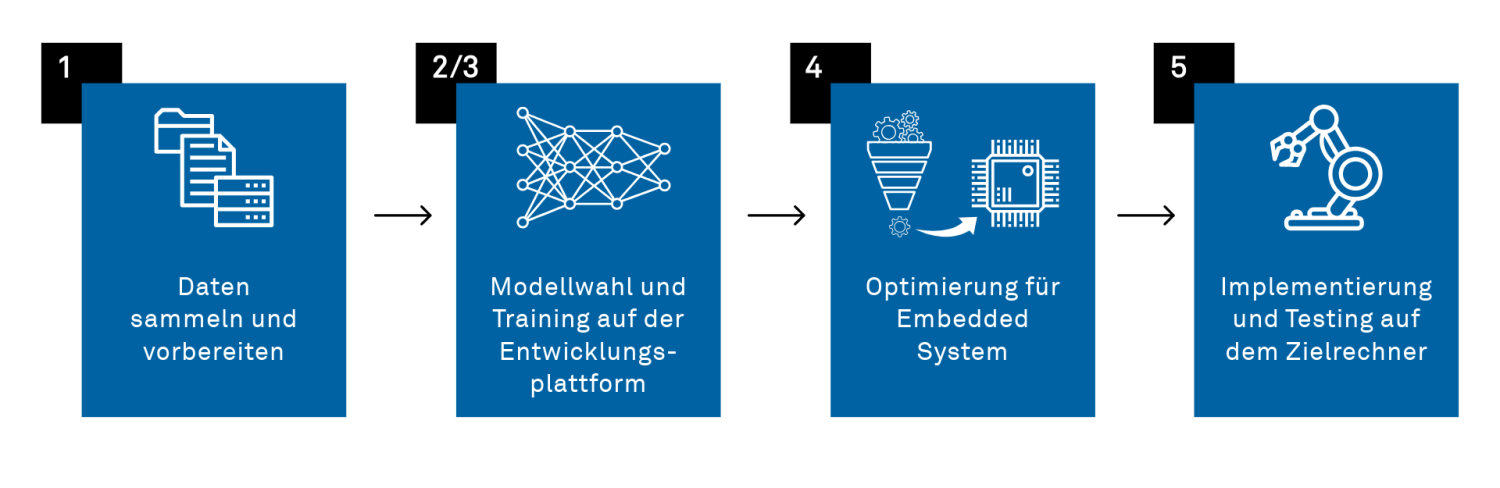
Entwicklungsschritte eines Embedded KI Projektes
Zur Unterstützung der erläuterten Entwicklungsschritte stehen verschiedene Tools zur Verfügung. Nachfolgend ein Überblick über verbreitete Bibliotheken und Frameworks für Embedded AI:
| Library/Framework | Ziel Hardware | Eigenschaften |
|---|---|---|
| TensorFlow Lite | Mobile, Embedded, Mikrocontroller | Leichtgewichtig, unterstützt Quantisierung |
| PyTorch Mobile | Mobile, Embedded | Optimiert für Android/iOS |
| CMSIS-NN | ARM Cortex-M Mikrocontroller | Hoch effizient, kleiner Footprint |
| STM32Cube.AI | STM32 Mikrocontroller | Optimiert für STM32 Hardware |
| Apache TVM | Fast überall | Cross-Plattform, Modell Optimierungen |
Was passiert auf dem Zielrechner?
Wie bereits erwähnt, bestehen die Berechnungen hauptsächlich aus Multiplikationen und Additionen. Die Daten werden so aufbereitet, dass sie mit Matrizenoperationen verarbeitet werden können. Die meisten Berechnungen sind Matrix-Multiplikationen (die Gewichte der Synapsen einer Schicht) mit einem Vektor (die Eingänge der Neuronen dieser Schicht).
Glücklicherweise sind GPUs (Grafikprozessoren) ideal für solche Berechnungen geeignet, da sie ähnliche Operationen auch in der Bildverarbeitung durchführen. Sie ermöglichen es, viele Berechnungen parallel auszuführen, was die Effizienz erheblich steigert. Mit der Zeit wurden spezialisierte Hardwarelösungen wie die TPU (Tensor Processing Unit) und später die NPU (Neuromorphic Processing Unit) entwickelt, die speziell für Deep Learning optimiert sind.
Auch in der Embedded-Welt hat sich viel getan. Es gibt immer mehr dedizierte Hardwarelösungen, die auf die Berechnung neuronaler Netze zugeschnitten sind.
In der nachfolgenden Tabelle werden einige dieser Produkte genauer vorgestellt.
| Kategorie | Typ | Merkmale | Preis | Anwendungsbeispiele |
|---|---|---|---|---|
| Gaming Grafikkarte | Nvida GeForce 5090 | Bis 1000 W (total) Bis 3352 AI TOPS 3.3 TOPS / W 32 GB RAM | ~3000 $ | LLMs die nicht zu gross sind (z.B. GPT-3, GPT-4 ist bereits zu gross) |
| High-End Embedded Rechner für KI | Nvida Jetson Orin NX | 10 – 25 W 70 – 100 AI TOPS 4 TOPS / W 16 GB RAM | ~700 $ | Small Language Models (SLM). Es gibt viele die zwischen 600 MB und 4 GB gross sind. Objekterkennung mit den besten Deep Neural Networks und hohe Framerate (Z.B. YOLOv7) |
| Low-Power KI Zusatzrechner | Intel Movidius Myriad X | 1.5W 4 AI TOPS 2.6 TOPS / W 2.5 MB RAM | ~80 $ | Echtzeit Objekt Erkennung mit kleine Netze (z.B. MobileNet v2 oder TinyYolo) Gesichtserkennung und biometrische Authentifizierung Optische Charakter Erkennung Autonome Navigation und Kollisions-vermeidung Fussgänger- und Fahrzeugerkennung Predictive Maintenance |
| Mikrocontroller mit KI Unterstützung | STM32N6 | 225 – 417 mW 0.6 AI TOPS 1.4 - 2.6 TOPS / W 4.2 MB RAM | ~15 $ | Sprachkommandos Erkennung Audio Scene Erkennung Einfache Objekterkennung in Bildern Anomalie Feststellung Predictive Maintenance Handzeichen-erkennung Lärmfilter in Audiosignale |
| Low-Power Mikrocontroller | STM32L5 | 40 mW Sehr abhängig von der Anwendung 256 kB RAM | ~5 $ | Keyword Spotting Gestenerkennung mit Beschleunigungssensor Bildklassifizierung mit sehr niedriger Auflösung Anomaly detection |
Fazit
KI ist längst nicht mehr nur auf leistungsstarke PCs oder grosse Rechenzentren beschränkt.
Sie kann auch auf Embedded Systemen oder sogar Mikrocontrollern eingesetzt werden, um eine Vielzahl von Anwendungen zu ermöglichen.
Es gibt inzwischen zahlreiche Tools, die die Umsetzung solcher Projekte erleichtern, und viele neue Hardware-Entwicklungen, die über dedizierte KI-Beschleuniger verfügen. Diese spezialisierte Hardware ermöglicht es, KI-Berechnungen effizient und energiearm durchzuführen.
Bekannte Modelle für die Objekterkennung wurden für den Einsatz auf kleinen Rechnern optimiert – oft mit nur minimalem Präzisionsverlust. Dadurch ist es heute möglich, Objekte in Echtzeit auf einem Mikrocontroller zu erkennen oder zu verfolgen – und das bei einem Stromverbrauch von nur wenigen hundert Milliwatt.
Diese Fortschritte eröffnen völlig neue Möglichkeiten für KI-Anwendungen in Bereichen wie Transport, Industrie 4.0, Internet of Things oder Smart Cities.
Wir unterstützen Sie gerne bei Ihrem nächsten Embedded KI Projekt.
Jetzt Kontakt aufnehmen und KI-Embedded Projekt starten >
Noch unentschlossen?
In Kürze werden wir einen weiteren Beitrag publizieren, in welchem wir eine praktische Umsetzung der erwähnten Technologien auf einem kleinen Mikrocontroller vorstellen.

Lukas Frei
MSc Universität Bern und BFH in Biomedical Engineering
Embedded Software Engineer
Über den Autor
Lukas Frei ist seit vier Jahren als Embedded Software Engineer bei der CSA tätig und hat sich auf die Entwicklung von Firmware in C/C++ für STM32-Systeme spezialisiert.
In den letzten Jahren hat er umfangreiche Erfahrung in der Entwicklung, dem Testen und der Optimierung von Firmware für eine Vielzahl von Anwendungen gesammelt – darunter in den Bereichen Industrie, Transport und Medizintechnik.
Mit seiner fundierten Erfahrung in der Entwicklung von Embedded Software und einem grossen Interesse an Künstlicher Intelligenz bringt er frische Perspektiven in Ihre Projekte.