Embedded Geräte mit Künstlicher Intelligenz:
Keyword Spotting mit TinyML und Cortex-M4
Theoretisch verstanden ist praktisch noch nicht umgesetzt.
Da wir wissen, dass Herausforderungen oft erst bei der konkreten Anwendung sichtbar werden, möchten wir die Theorie zu KI auf Embedded Systemen aus dem Blogbeitrag vom 4. März 2025 mit einem konkreten Beispiel untermauern.
Ziel ist eine «Keyword Spotting» Anwendung auf einem Cortex-M4 Mikrocontroller die zeigt, dass KI auch in der Embedded Welt Einzug gehalten hat.
Den erwähnten Blogbeitrag zum Nachlesen finden Sie hier: https://www.csa.ch/blog/ki-in-embedded-systemen-so-gehts
Anwendungsfall «Keyword Spotting»
Leistungsintensive Geräte werden unter anderem aus energietechnischen Gründen, welche auch durch EU Regulatorien vorgeschrieben sind, in Standby- / Schlafmodus gesetzt.
Dabei sind die leistungsstarken Prozessoren und die Internetverbindung ausgeschaltet. Ein kleiner Embedded Microcontroller muss folglich ohne fremde Hilfe das restliche Gerät aufwecken können. Dies nennt man «Keyword Spotting».
Bekannte Beispiele dafür sind «Alexa!», «Okay Google!» oder «Hey Siri».
Für viele scheint diese Technologie bereits trivial, es ist aber gleichzeitig ein Paradebeispiel für eine Anwendung eines neuronalen Netzes auf einer Plattform mit sehr limitierten Ressourcen.
Warum ist dieser Mehraufwand nötig?
Ein wesentlicher Faktor ist der Energieverbrauch. Darüber hinaus spielen Datenschutz und der Schutz der Privatsphäre eine zentrale Rolle.
Wollen wir, dass ein Gerät ständig mithört und unsere Daten auswertet?
Möchten wir nicht, dass der Dienst nur dann gebraucht wird, wenn wir das explizit erlauben?
Und da kommt die erwähnte «Keyword Spotting» Anwendung ins Spiel. Ein speziell für die Erkennung weniger Schlüsselwörter trainiertes Modell kann so kompakt gehalten werden, dass es kaum Rechenleistung oder Energie benötigt, und ganz ohne permanente Internetverbindung auskommt.
Das Embedded-Gerät hört zwar kontinuierlich mit, analysiert jedoch ausschliesslich das Aktivierungswort. Alle übrigen Audiodaten werden unmittelbar verworfen..
Zudem geschieht der ganze Prozess nur lokal.
Der Workflow
Dieses Kapitel beschreibt den von uns angewandten Workflow im Projektverlauf.
1. Designanforderungen bestimmen
Dies scheint auf den ersten Blick trivial. Ein kleines Gerät soll auf Spracheingaben reagieren und eine Aktion ausführen, sobald ein spezifisches Wort identifiziert wird.
Es stellen sich aber weitere Fragen:
Bezüglich Endbenutzer:
- Welche Sprache und mit welchem Akzent wird gesprochen?
- Wird geflüstert oder laut gesprochen?
- Soll das Gerät nur auf eine Stimme reagieren? Was passiert, wenn meine Frau oder meine Kinder das gleiche Wort sagen?
Bezüglich Einsatzort:
- Befinden wir uns ständig in einer ruhigen Umgebung oder gibt es Hintergrundgeräusche?
- Müssen wir das Aktivierungswort auch bei Lärm entdecken können?
- Angenommen unser Gerät sitzt in unserem Wohnzimmer, da ist es meistens ruhig. Was ist, wenn wir das Fenster öffnen und draussen eine Baustelle ist?
Bezüglich Datensicherheit:
- Was passiert mit den aufgenommenen Audiodaten?
- Werden sie zwischengespeichert oder gleich wieder verworfen?
- Gehen sie in die Cloud zur weiteren Verarbeitung oder nicht?
Die Liste könnte noch beliebig erweitert werden. Sie veranschaulicht jedoch viele Aspekte, deren man sich bewusst sein muss, bevor gestartet werden kann.
Unser Beispiel soll stark vereinfacht werden, also definieren wir unsere Anforderungen wie folgt:
- Wörter «Yes» und «No» sollen erkannt werden.
- Wird «Yes» erkannt, soll eine grüne LED aktiviert werden.
- Wird «No» erkannt, soll eine rote LED aktiviert werden.
- Werden Geräusche erkannt, jedoch keines der vorgegebenen Wörter, soll eine blaue LED aktiviert werden.
- Das Gerät wird nur in einer ruhigen Umgebung angewendet (Büro).
- Das Gerät soll bevorzugt die Stimme des Autors erkennen, es wird aber weder speziell personalisiert, noch diversifiziert.
- Unser Gerät hat keine Anbindung an das Internet.
- Daten werden direkt nach der Bearbeitung wieder verworfen.
2. Daten sammeln und aufbereiten
Nun beginnt die Datensammlung, die als Grundlage für das spätere Training unseres Modells dient.
Dies ist oft der aufwändigste und herausforderndste Teil. Wir brauchen ein Datenset, welches tausende von Wörtern enthält und gleichzeitig repräsentativ für die beabsichtigte Umgebung ist.
Das Gerät soll zwar «nur» im Büro zum Einsatz kommen, aber auch da gibt es Hintergrundgeräusche.
Sollen diese Daten selbst gesammelt werden, kann dies ein langer und aufwändiger Prozess sein. Es werden nicht nur die Wörter «Yes» und «No» gebraucht, sondern auch noch möglichst viele andere Wörter, sowie Tonschnipsel, die gar kein Wort enthalten.
Dieser Prozess wird stark vereinfacht, indem ein bestehender Datensatz verwendet wird.
Es gibt mehrere frei verwendbare Datensätze [1], ein Grossteil davon in Englisch. Da das Gerät für «Yes» und «No» trainiert werden soll, verwenden wir einen Datensatz, der diese Worte bereits enthält.
Ein geeigneter Datensatz ist «speech_commands» von Pete Warden [2].
Dieser enthält Tausende von Aufnahmen für diverse Wörter, so auch für «Yes» und «No», mit deren unser Modell trainieren kann.
Falls eine spätere Personalisierung (z. B. auf eine bestimmte Stimme) gewünscht ist, wäre jetzt der richtige Moment, eigene Sprachaufnahmen zu machen und diese zum Trainingsdatensatz hinzuzufügen.
[1] Eine Auflistung findet man hier: https://github.com/jim-schwoebel/voice_datasets
[2] https://arxiv.org/pdf/1804.03209: Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
2.1 Audiodaten aufbereiten
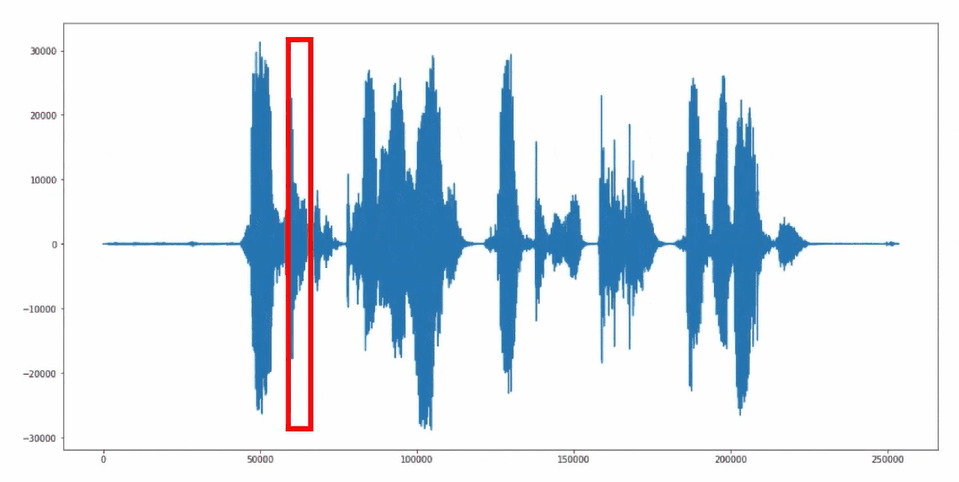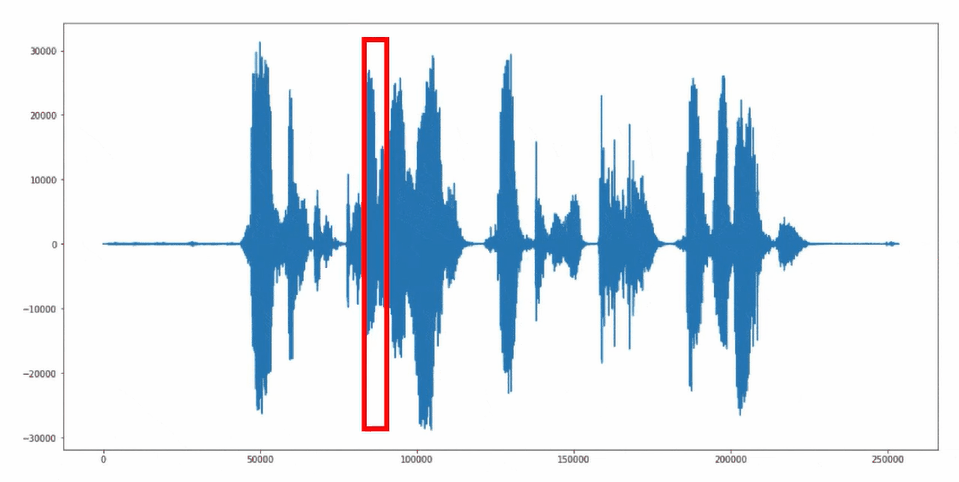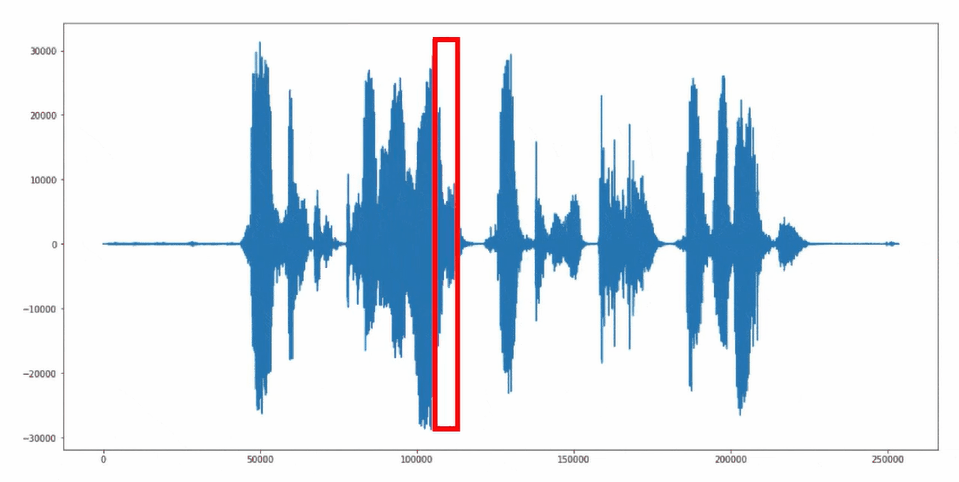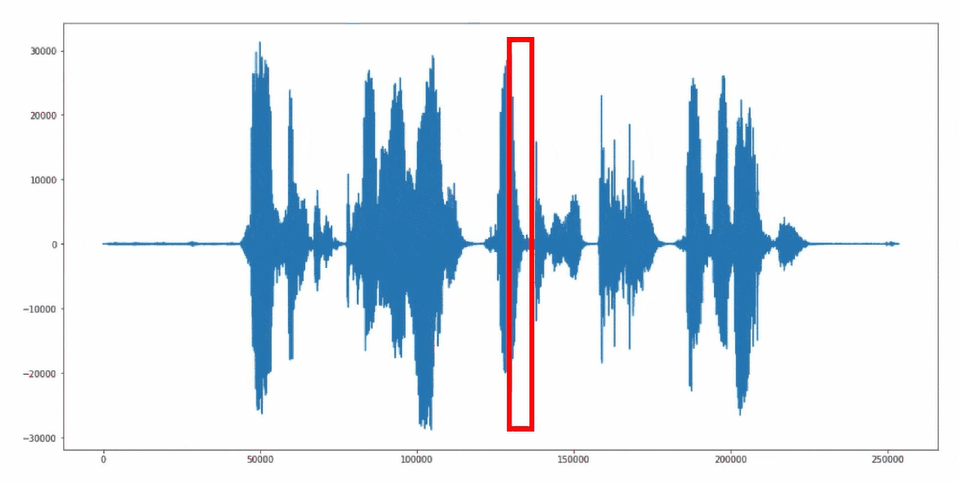
Bei Audiodateien werden die Informationen des Schwingungsverlaufs gespeichert, ein wertdiskretes Signal im Zeitbereich. Das Modell soll die charakteristischen Merkmale dieser Signale extrahieren können. Dies ist mit Signalen im Zeitbereich aber schwierig.
Die folgende Abbildung zeigt:
- Gleiche Wörter können sehr unterschiedlich aussehen
- Unterschiedliche Wörter ähneln sich oft stark im Zeitbereich
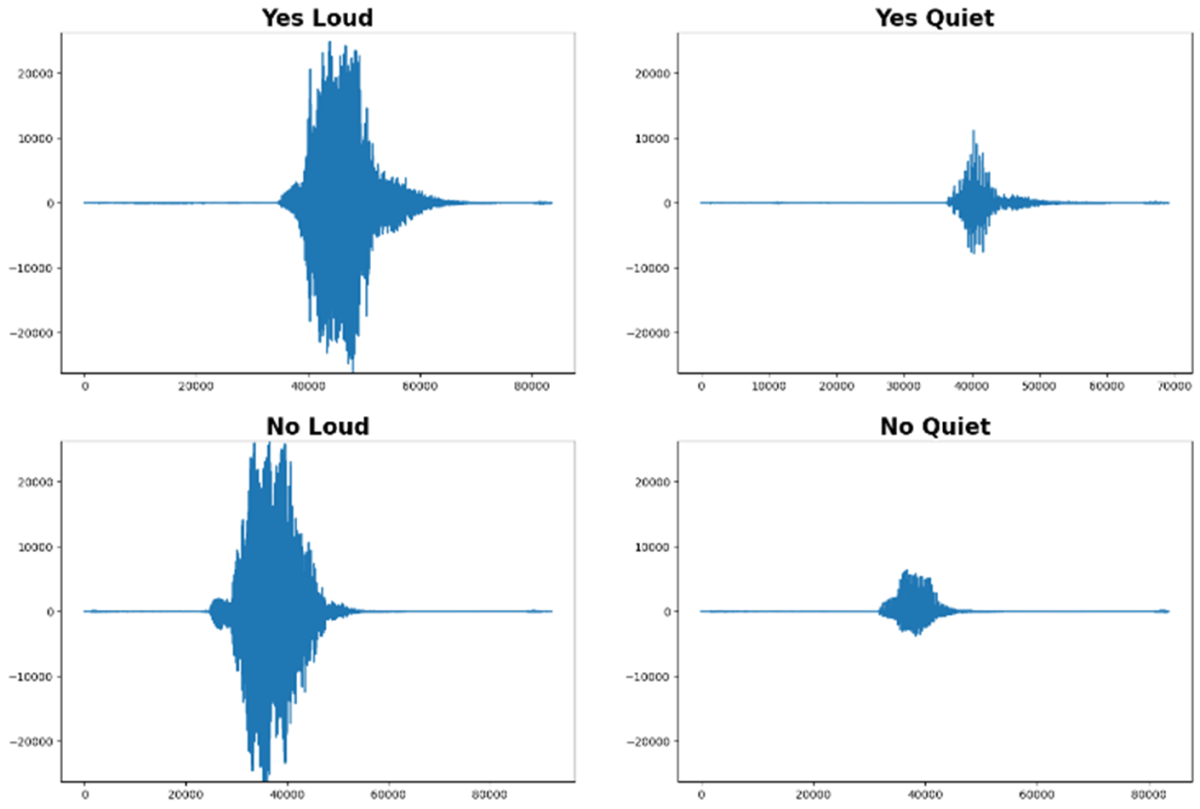
Auch eine reine Konvertierung in den Frequenzbereich (Fouriertransformation), macht die charakteristischen Merkmale nicht deutlicher. Es kann nun vielleicht die Tonhöhe oder die Stimmfarbe erkannt werden, doch für unsere Anwendung reicht dies nicht aus.
Ziel ist es, den Inhalt der Aussage zu erkennen, nicht die Stimme oder Tonlage der sprechenden Person.
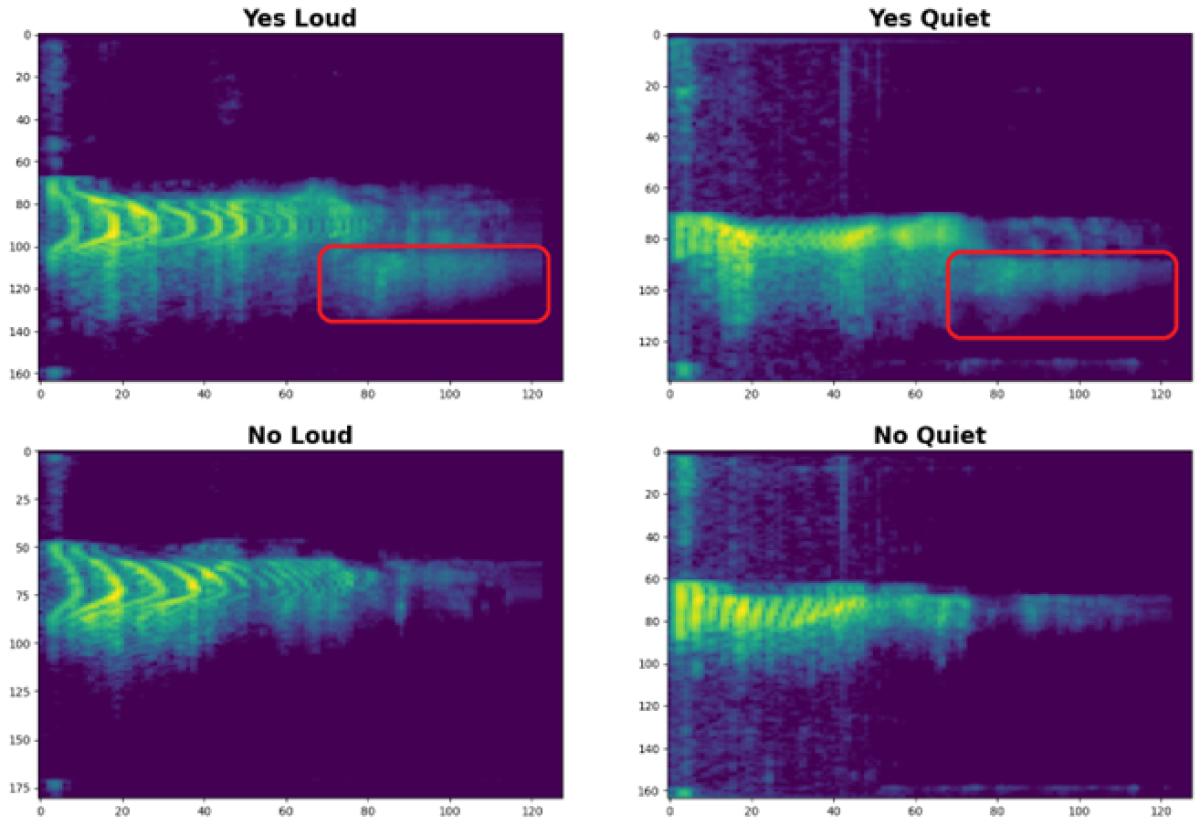
Die charakteristischen Merkmale eines Wortes werden erst im Spektrogramm ersichtlich, einer Darstellung des zeitlichen Verlaufs des Frequenzspektrums.
Diese Ähnlichkeiten können noch etwas stärker hervorgehoben werden, indem der relevante Frequenzbereich angepasst und der Kontrast zwischen leise und laut erhöht wird.
Bei genauer Betrachtung können wir nun eindeutig zwischen «Yes» und «No» unterscheiden, egal wie laut gesprochen wurde.
Für uns Menschen ist diese Unterscheidung offensichtlich, ein KI-Modell muss jedoch gezielt darauf trainiert werden, diese Unterschiede eindeutig zu erkennen.
Durch diese Aufbereitung wird unser Datensatz nun zur soliden Basis für das anstehende Modelltraining.
3. KI-Modell entwickeln und trainieren
Nun richten wir unseren Fokus auf das neuronale Netz. Wie es funktioniert und welche Neuronen- sowie Schichttypen darin enthalten sein können, haben wir bereits im oben genannten Blogbeitrag erläutert.
Wir haben uns für die Verwendung von TensorFlow entschieden.
TensorFlow bietet mit TensorFlow Lite und TensorFlow Lite Micro einen vordefinierten Pfad zur Programmierung von Embedded Devices. Alternativen wie z.B. Pytorch benötigen ein laufendes Betriebssystem wie zum Beispiel iOS, Android oder ein embedded Linux. TensorFlow braucht das nicht und kann auch «Bare-Metal» verwendet werden.
Während der Datenaufbereitung wurden die Audiosignale in Spektrogramme umgewandelt. Wir können also ein bestehendes Modell anwenden, das auf das Extrahieren von Features aus Spektrogrammen / Bilddateien spezialisiert ist.
Auch wenn hochspezialisierte Modelle nur einen begrenzten Funktionsumfang bieten, tun sie dies äusserst effizient und sind daher ideal für Umgebungen mit begrenzten Ressourcen.
3.1 TinyConv
Wir verwenden das tiny_conv Modell von TensorFlow.
Dieses besteht aus vier Layern welche für unsere embedded Applikation ausreichen.
- Input Layer
Hier werden die in Kapitel 2.1 genannten Schritte unternommen, um die Daten vom Mikrofon in ein Spektrogramm umzuwandeln (Reshape).
- Convolution Layer
Dieser Layer filtert die Features aus den Spektrogrammen.
- Fully Connected Layer (auch Dense Layer genannt)
Hier werden die Wahrscheinlichkeiten berechnet, welches Wort anhand der gefilterten Features erkannt wurde.
- Output Layer
Aus den oben genannten Wahrscheinlichkeiten wird nun eine Klassifizierung vorgenommen. Dies geschieht über die SoftMax Aktivierungsfunktion.

3.2 Transfer Learning
Wie die bereits etablierten Anwendungen zum Aufwecken von bekannten KI-Assistenten suggerieren, sind wir nicht die Ersten, die ein solches Modell trainieren. Ebenfalls sind wir nicht die Ersten, die genau diesen bestehenden Datensatz dafür verwenden, schliesslich wurde dieser Datensatz genau für solche Anwendungen aufgebaut.
Es gibt frei verwendbare Modelle, die bereits mit diesem Datensatz trainiert wurden, so dass wir unserem Modell tagelanges Training ersparen können.
Dazu können wird ein Snapshot von einem Modell verwenden, um zusätzliches Training darauf aufzubauen. TensorFlow bietet dazu die Möglichkeit, während des Trainings Checkpoints zu definieren, von denen aus der Trainigsprozess jederzeit fortgesetzt werden kann.
Mit den spezifischen Trainingsdaten wird das Modell ab dem Checkpoint weitertrainiert. Dabei bleibt ein Teil der Daten für die anschliessende Validierung reserviert. Daraus resultiert ein finaler Checkpoint, der dazu geeignet ist, Inferenzen auf dem Gerät durchzuführen.
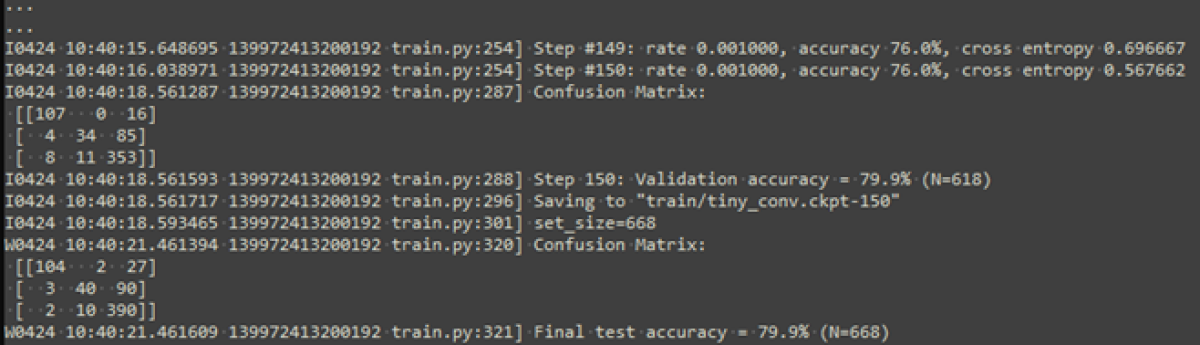
Die Genauigkeit ist mit ca. 80% nicht sehr hoch, könnte jedoch mit anpassungen im Training, dem Modell oder den Trainingsdaten verbessert werden.
Dies würde den Rahmen des Testprojekts aber sprengen.
4. Modell konvertieren, optimieren und deployen
Die Anforderungen an die Modelleigenschaften werden vor allem durch die Hardware vorgegeben, auf der es später laufen soll.
Wir verwenden einen nRF52480 Mikrokontroller von Nordic. Dieser Cortex-M4F läuft mit einer Taktfrequenz von 64MHz und verfügt über 1MB Flash und 256KB RAM.
Das Modell muss also sehr klein sein, damit es auf der Hardware lauffähig ist. Dies erreichen wir, indem das Modell so stark reduziert wird, dass es nur noch die effektiv verwendeten Funktionalitäten enthält.
Zunächst wird der letzte Checkpoint in ein Modell konvertiert, welches nur Inferenzen (Klassifizierungen) machen kann. Dieser Vorgang wird als "Freeze" bezeichnet:
Dabei wird das Modell auf einem bestimmten Stand „eingefroren“.
Ein weiteres Training ist danach nicht mehr möglich – aber auch nicht mehr erforderlich.
4.1 TensorFlow zu TensorFlow Lite
Bisher haben wir uns im Bereich von TensorFlow bewegt. Dem Teil des KI-Frameworks, der für das Erstellen und Trainieren des Modells verantwortlich ist.
Nun generieren wir aus dem eingefrorenen Modell ein TensorFlow Lite Modell. Dabei werden unter anderem die bis anhin verwendeten Fliesskommazahlen auf 8-Bit Integer quantisiert.
Ausserdem wird der Trainingsdatensatz auf die gleiche Art konvertiert, so dass das Modell nach der Konvertierung getestet werden kann.
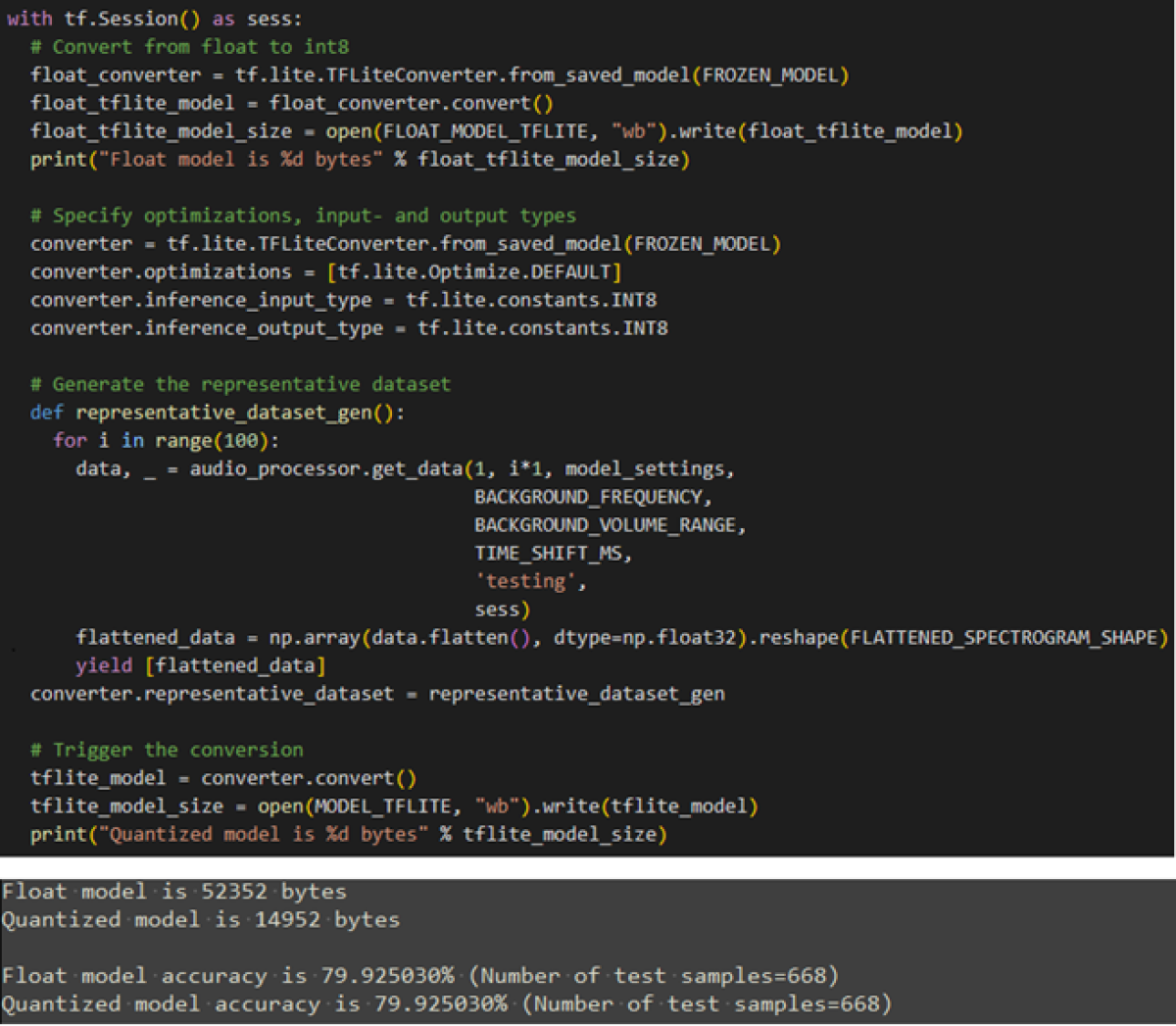
Durch die Konvertierung gab es keine Einbussen in der Genauigkeit, wie der obige Output aufzeigt.
4.2 TensorFlow Lite zu TensorFlow Lite Micro
Nun sind wir an der letzten Station des TensorFlow Frameworks angekommen.
Es soll ein Modell für Inferenzen generiert werden, welches auf der Hardware lauffähig ist. Das übernimmt für uns TensorFlow (TF) Lite Micro.
Hier gehen wir mit der Kompression bis ans Limit, indem alle Funktionalitäten, die nicht zwingend gebraucht werden entfernt. TF Lite Micro ist spezifisch für den Einsatz auf embedded Geräten entwickelt worden. So werden zum Beispiel keine dynamischen Speicher alloziert, es wird kein Filesystem benötigt und es werden keine Funktionen der Standardbibliothek verwendet.
TF Lite Micro ist somit auch auf verschiedene Plattformen portierbar.
Die folgenden Unterkapitel beschreiben die Verwendung von TF Lite Micro
4.2.1 OpResolver
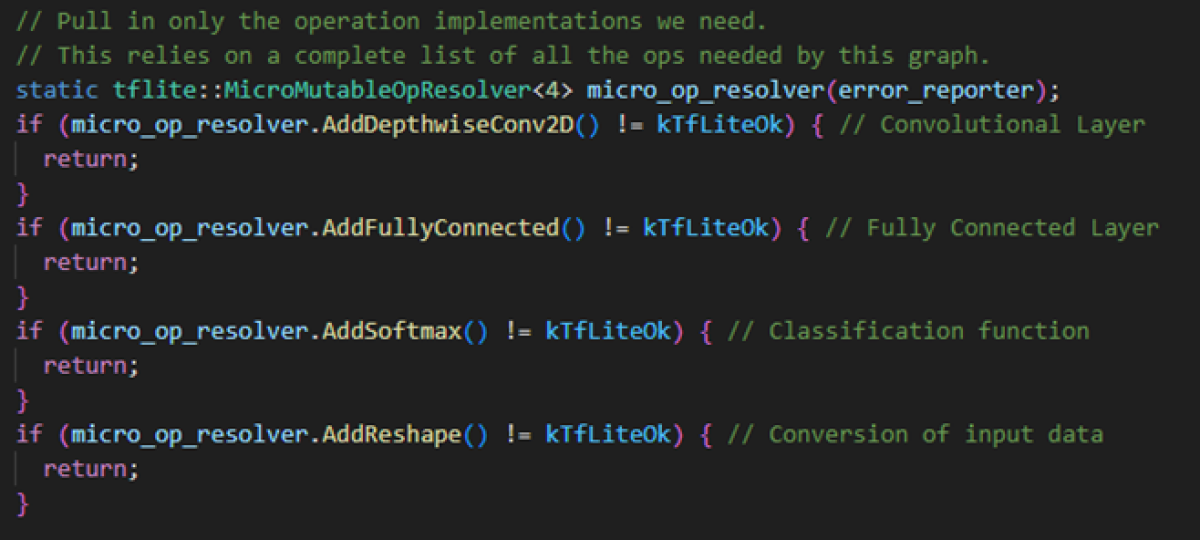
Der Operation Resolver gibt an, welche Funktionen der TensorFlow Bibliothek verwendet werden sollen und welche nicht. Es ist abhängig davon, von welchem Typ die Layer sind, und welche Funktionen sie für die Verarbeitung der Input Daten oder für die Klassifizeriung brauchen.
In unserem Fall sind dies die folgenden Funktionen:
4.2.2 Interpreter
Interpretieren im Softwarekontext heisst, ein Programm auszuführen, indem einer Datenstruktur im Speicher gefolgt wird.
Zum Vergleich: Beim kompilierten Ansatz wird die Ausführung eines Programms zur Kompilierzeit festgelegt.
Wenn Code auf einem embedded Gerät ausgeführt wird, bevorzugen wir eine kompilierte Sprache, da eine Zeile Code in 3-4 Prozessorinstruktionen übersetzt wird. Wenn diese Zeile Code interpretiert wird, müsste diese zuerst dem Interpreter übergeben werden, damit er sie in Prozessorinstruktionen umwandeln kann. Der Overhead wäre grösser als der ausführbare Code selbst.
Bei einem KI-Modell ist das anders. Jeder Aufruf des Modells erzeugt tausende von Instruktionen, sodass der Overhead, der beim Übergeben entsteht, vernachlässigbar klein ist. Es spielt also keine Rolle, ob das Modell kompiliert oder interpretiert wird.
Der Interpreter hat jedoch entscheidende Vorteile. Zum einen kann das Modell ausgetauscht werden, ohne dass der Code neu kompiliert werden muss. Das lässt kleine Iterationszyklen zu, falls das Modell verfeinert wird.
Zusätzlich kann der gleiche Operator Code für verschiedene Modelle im System gebraucht werden.
Schlussendlich ermöglicht es das gleiche Modell in verschiedenen Systemen zu verwenden.
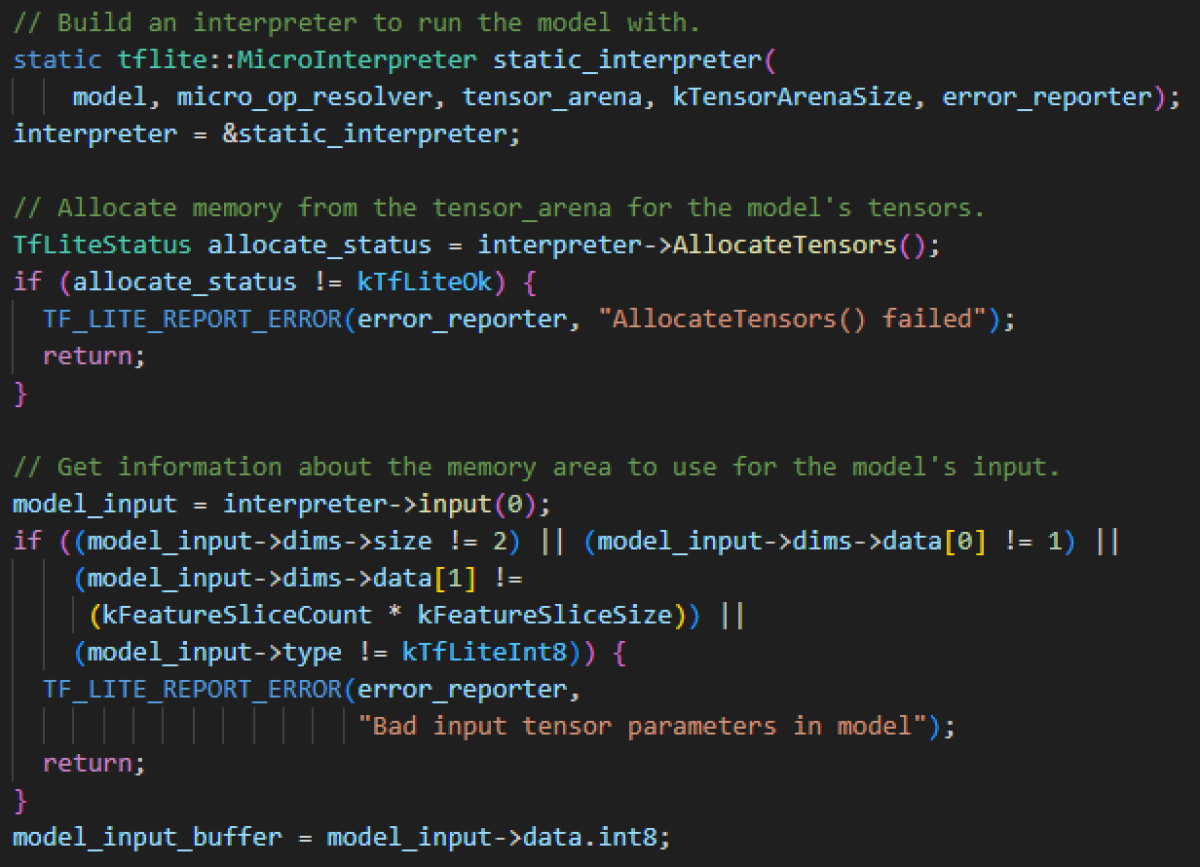
Im obenstehenden Code ist ersichtlich, dass dem Interpreter das Modell, den OpResolver und eine TensorArena übergeben werden muss.
Die TensorArena ist ein Speicherbereich, den der Interpreter für Input, Output und Zwischenschritte verwenden kann, da auf dynamische Speicherallokation verzichtet wird.
Die Grösse ist abhängig vom verwendeten Modell und muss dementsprechend angepasst werden.
4.2.3 FlatBuffer
Das Modell selbst wird in einem FlatBuffer gespeichert. Ein FlatBuffer ist ein Array von Bytes, welches die Operationen und Gewichtungen des Modells enthalten. Zusätzlich werden Metadaten wie Version, Quantisierungsgrad oder Parameter darin gespeichert.
Das Format, in welchem dieses Array ausgelesen wird, ist in einem Schema File definiert. Dieses spezifiziert, wo bestimmte Elemente in der Datenstruktur zu finden sind. Der Kompilator generiert daraus Code, um auf diese Elemente in der richtigen Art und Weise zuzugreifen.
Der FlatBuffer wird nicht in der TensorArena gespeichert, sondern in einem Read-Only Bereich, typischerweise im Flash, da sich unser Modell zur Laufzeit nicht verändern kann.
Umsetzung und Resultat
Für die Anwendung des KI-Modells auf dem Embedded Gerät muss noch etwas Code geschrieben werden. Dieser beinhaltet insbesondere das Auslesen des Mikrofons, das Übergeben dieser Daten an das Modell, das Auswerten der Ergebnisse und schlussendlich die Ansteuerung des LEDs in der entsprechenden Farbe.
Für das Auslesen und die Weiterverarbeitung der Mikrofonsignale wird der «Sliding-Window» Ansatz angewendet. Dabei werden die Audiosignale fortlaufend als 1 Sekunden Ausschnitte gruppiert und an das neuronale Netzwerk übergeben.
Sliding-Window Ansatz
Source Code "Keyword Spotting" Anwendung
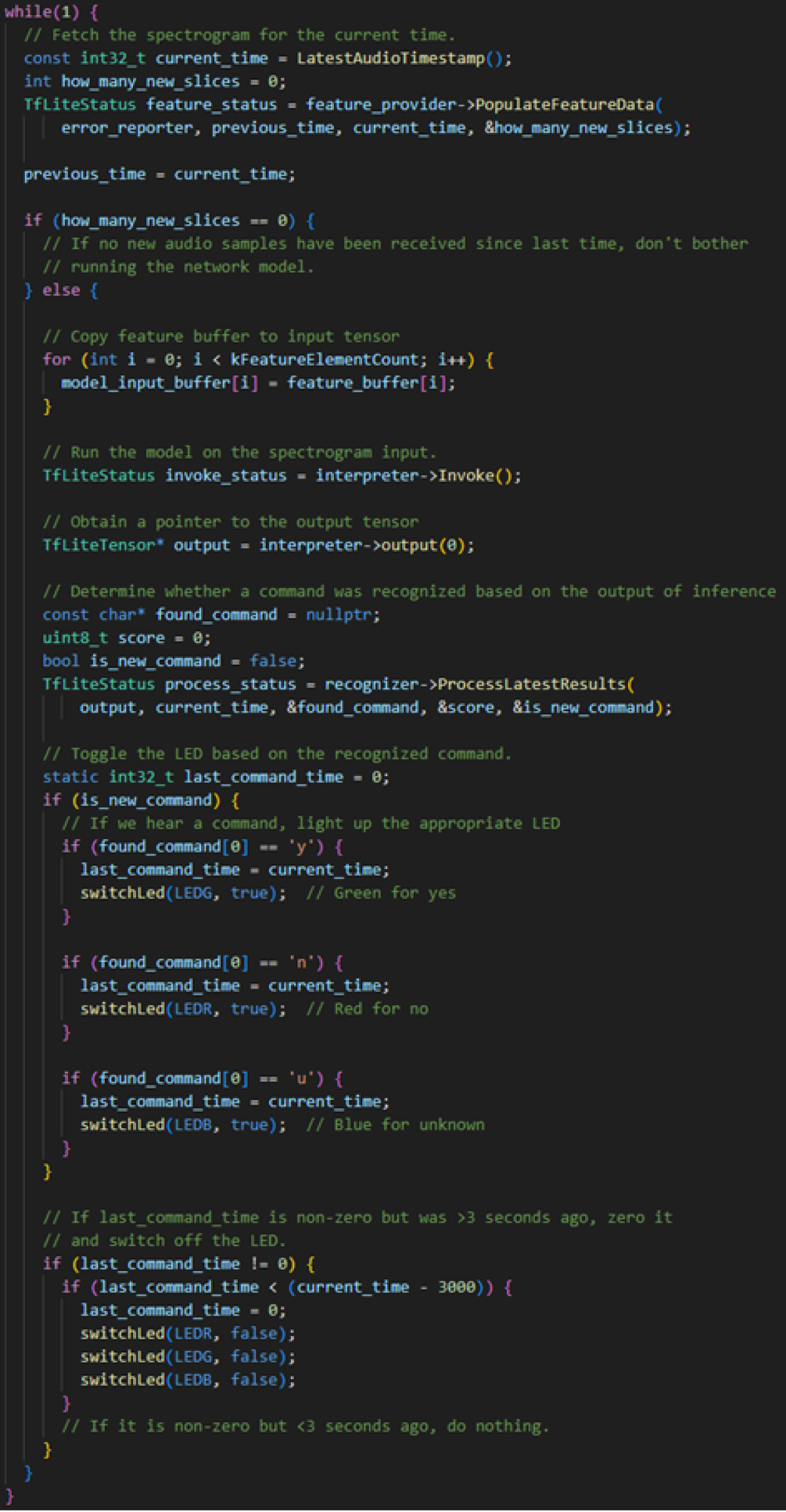
Fazit
Wie im letzten Beitrag zum Thema KI erwähnt, ist KI in Embedded Systemen angekommen und eröffnet zahlreiche neue Anwendungsmöglichkeiten.
Wir haben für unser Beispiel einen herkömmlichen Mikrokontroller verwendet. Jedoch gibt es heute Chips mit dedizierten KI-Beschleuniger und spezialisierter Hardware auf dem Markt. Unser Beispiel zeigt auf, dass diese jedoch nicht zwingend nötig sind, um ein funktionierendes KI-Projekt umzusetzen.
Wir verstehen diese Technologie und sind gespannt, welche spannenden Projekte und Anwendungsfelder sich damit künftig in der Embedded-Welt realisieren lassen.
Mit unserem Know-how gestalten wir diese Zukunft aktiv mit und unterstützen Sie gerne bei Ihrer nächsten Entwicklung.

Mathieu Bourquin
BSc BFH in Elektro- und Kommunikationstechnik
Embedded Software Engineer
Über den Autor
Mathieu Bourquin arbeitet seit vier Jahren als Embedded Software Engineer bei der CSA.
Er unterstützt Kunden in der Medizinaltechnik und ist Spezialist für das Entwickeln von Firmware in C/C++ und die Umsetzung von funktionaler Sicherheit. Sein Interesse an neuen Technologien und seine Motivation sich stetig weiterzubilden haben ihn unweigerlich zur KI-Technologie geführt.